YOLOv8 - 自定义数据集并训练
参考视频:
【yolov8】从0开始搭建部署YOLOv8,环境安装+推理+自定义数据集搭建与训练,一小时掌握_哔哩哔哩_bilibili
本文参考以上视频第5部分
基础
配置文件:default.yaml
YOLOv8持续更新,项目结构会有变化
快捷查找配置文件方式:ctrl+shift+N,然后选择所有或文件,之后输入default搜索即可
default.yaml中参数可以写在yolo CLI中
推理命令:
yolo task=detect mode=predict model=yolov8n.pt conf=0.25 source='...'
task:任务
mode:模式
model:选择自己训练的模型或官方模型
conf:置信度
source:图片/视频路径
数据集的结构与制作
datasets文件结构
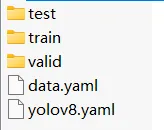
数据结构
datasets
│
├─ test
│ ├─ images
│ │ └─ ······
│ └─ labels
│ └─ ······
│
├─ train
│ ├─ images
│ │ └─ ······
│ └─ labels
│ └─ ······
│
├─ valid
│ ├─ images
│ │ └─ ······
│ └─ labels
│ └─ ······
│
├─ data.yaml
└─ yolov8n.yaml
yolov8.yaml:从官网拉取下来的yolov8项目中包含,复制到datasets文件夹下面即可。
data.yaml内容:
train: ../datasets/train/images # 此处建议写绝对路径 |
标注格式转换
yolov8只支持txt类型标注!!见官网原文
参考文档:
目标检测,将xml格式的标签数据集转换为yolov8(txt)格式_xwyd转yolo格式-CSDN博客
import os |
将数据集划分为test,train,valid
import os |
注1:想使用以上划分代码,则必须严格遵守本文datasets文件结构
注2:填写正确的数据集路径,如images文件夹下可能还有子文件夹而非直接是图片文件,labels同理
用自定义数据集训练
训练模型
开始训练:
yolo task=detect mode=train model=datasets/yolov8n.yaml data=datasets/data.yaml epochs=10000 imgsz=640 resume=True workers=2 batch=16 amp=False
yolo task=detect mode=train model=datasets/yolov8n.yaml data=datasets/data.yaml epochs=500 imgsz=640 resume=True workers=2 batch=16 amp=False
可能出现的问题 ①
终端中可能显示正在等待下载Arial.ttf,则点击其后的网站下载该文件即可。
可能出现的问题 ②
WARNING No labels found in D:\Pycharm\ultralytics-main\datasets\train\labels.cache, training may not work correctly.
查看数据集标注是否为txt类型。
可能出现的问题 ③
WARNING No labels found in D:\Pycharm\ultralytics-main\datasets\train\labels.cache, training may not work correctly.
可能出现的问题 ④
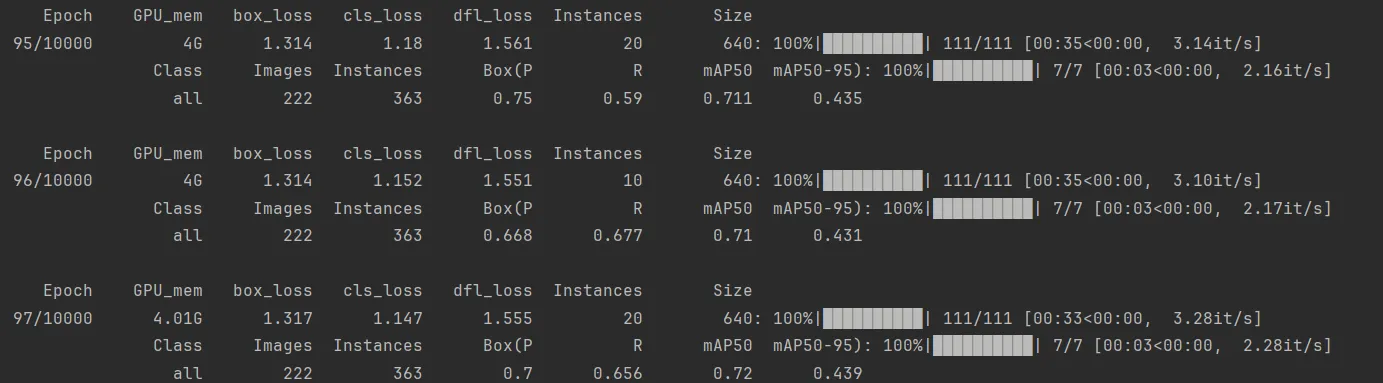
训练过程中数值出现nan:
这是有问题的,正常应该是一个数值:
解决方案:
① 设置batch,慢慢试,一般缩小,我使用16可以正常训练
② 设置amp=false
参考文档:
yolov5和yolov8在train时,出现box_loss、cls_loss、dfl_loss为nan,Box(P R mAP50 mAP50-95)为0的解决办法-CSDN博客

中断训练:按下Ctrl+C键来手动停止训练
中断续训:
将来自内容根的路径填入model中(注:填写last.pt的路径)
yolo task=detect mode=train model=runs/detect/train/weights/last.pt epochs=500 imgsz=640 resume=True workers=2
yolo task=detect mode=val model=runs/detect/train/weights/last.pt<br />yolo detect val model=./runs/detect/train/weights/best.pt

利用模型推理
填写best.pt的路径到model中yolo task=detect mode=predict model=runs/detect/train/weights/best.pt conf=0.25 source='ultralytics/assets/bus.jpg'
整体推理:yolo task=detect mode=predict model=runs/detect/train/weights/best.pt conf=0.25 source='datasets/test/images'
关于 ultralytics 8.0.48
对于ultralytics 8.0.48 需要找到yolov8n.yaml,不能像8.1.X版本,用yolov8.yaml
并且yolo detect train model=datasets/yolov8n.yaml data=datasets/data.yaml epochs=500 imgsz=640 resume=True batch=16yolo task=detect mode=train model=datasets/yolov8n.yaml data=datasets/data.yaml epochs=500 imgsz=640 resume=True batch=2 workers=2
KeyError: ‘depth_multiple’ · Issue #1 · OutBreak-hui/YoloV5-Flexible-and-Inference
一个重点报错!!使用以下命令行yolo detect train model=datasets/yolov8n.yaml data=datasets/data.yaml epochs=500 imgsz=640 resume=True batch=16
如果路径正确,却还报错路径找不到,说明 data.yaml 中没有使用绝对路径;或 yolo.yaml 文件 nc 没有写对;或文件命名有问题如 valid 写为 vaid